Google Cloud Dataflow 발표 (Google I/O 2014)

Google의 VP인 Urs Hölzle의 키노트 발표 내용입니다. Urs Hölzle은 구글의 8번째 직원이고, 최초의 기술자 출신 VP입니다.
흥미로운 점은 구글이 이미 1년 전부터 MapReduce를 사용하고 있지 않다는 사실입니다. 본래 구글이 만들어 낸 기술이고, 오픈소스 Hadoop으로 만들어져 여러 곳에서 쓰이고 있는데, 정작 만들어 낸 구글은 더 이상 쓰지 않는다고 합니다.
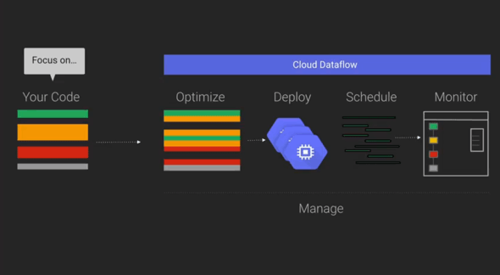
Cloud Dataflow는 빅데이터 분석 서비스입니다. FlumeJava와 MillWheel을 기반으로 만들어졌습니다. FlumeJava는 programming data-parallel computations을 위한 심플한 순수 자바 라이브러리이고, MillWheel은 구글에서 널리 쓰고 있는 low-latency data-processing applications을 만들기 위한 프레임워크입니다.
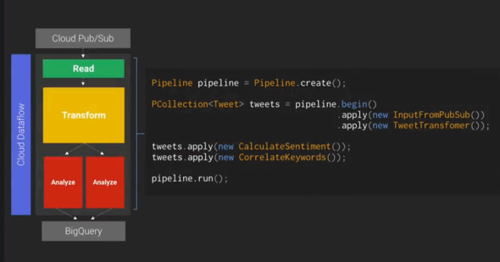
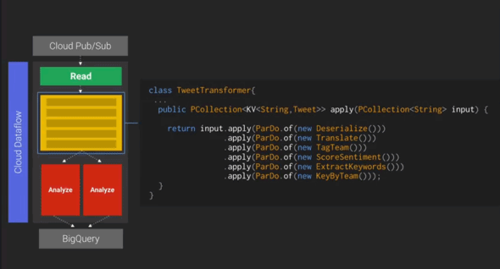
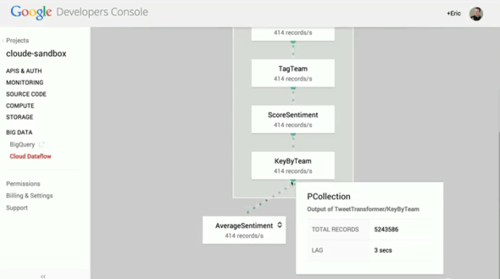
예시로 든 것은 스트림 처리지만 배치 잡도 가능합니다. 월드컵 관련 수백만 건의 트윗을 긍정·부정으로 분석하고 국가별로 분류하는 사례입니다. 먼저 Cloud Pub/Sub에서 JSON Stream을 읽고(Read), 데이터를 변환·매핑한 다음(Transform, 구글 번역 API 등도 활용할 수 있습니다) 분석(Analyze)합니다. Dataflow Console 화면에서는 지금까지 어느 정도 처리되었는지를 확인할 수 있습니다.
링크들
- Google Cloud Platform Blog: Reimagining developer productivity and data analytics in the cloud - news from Google IO
- Flumejava, Millwheel … No, not NSA codenames: The tech in Google Cloud’s data grokker • The Register
- Google adds a big data service and lots of monitoring to its cloud — Tech News and Analysis
- Google Launches Cloud Dataflow, A Managed Data Processing Service - TechCrunch
- 구글 데이터플로우, 하둡의 ‘대체제’가 아닌 이유