쿠버네티스 코드 읽기
요즘은 쿠버네티스(이하 k8s) 소스 코드를 읽고 있습니다. 디자인이 단순한 덕분에 비교적 읽기가 어렵지 않습니다. k8s가 이만큼 인기를 얻은 것도 그 단순함 때문일 것입니다.
디자인이 이렇게 단순해진 데에는 etcd의 역할이 컸다고 생각합니다. k8s는 etcd를 작업 큐(task queue)처럼 사용합니다. 메소스(mesos)는 같은 자리에 주키퍼(zookeeper)를 두는데, 바로 이 선택의 차이가 두 시스템을 크게 갈라놓은 것이 아닐까 싶습니다.
제가 오래전에 분석할 때만 해도 ‘미니언’이라는 용어를 쓰더니, 어느새 ‘노드’로 바뀌었습니다. ‘노드’라는 이름 덕분에, 그것이 무엇을 하는 것인지 따로 설명할 필요가 없어졌습니다. 이름을 바꾸던 무렵에 올라온 후보들을 보면 Koupi, Rower, Krew 같은 것이 있었습니다. ‘항해’에 빗대고 싶은 마음이 꽤 컸던 모양입니다. 하지만 비유나 추상보다는 구체적인 용어가 낫다고 생각합니다.
쿠버네티스를 소스에서 빌드
저는 제가 쓰는 솔루션을 직접 빌드해서 쓰는 것을 좋아합니다. 물론 제 개발 환경에 한해서입니다. 예를 들어 MySQL을 자주 쓰다 보니, 코드를 조금 손봐서 직접 빌드한 것을 씁니다. 문서를 읽기보다는 코드를 읽고, 로그를 찍어 보고, 직접 돌려 봅니다.
이렇게 하면 장점이 아주 많습니다. 아마 직접 해 본 사람만 느낄 수 있는 종류의 장점입니다. 리눅스 데스크톱을 운영체제로 쓰는 것, 그리고 vim을 쓰는 것도 장점이 무척 크다고 생각합니다. 그런데 막상 그 이유를 설명해 보라고 하면 말로 풀어내기가 어렵습니다. 사실 그 장점을 누리려면 수많은 문제를 스스로 해결해야 하기 때문이기도 합니다.
저 같은 이상한 사람을 그동안 본 적이 없었습니다. 그런데 회사에서 점심을 먹고 산책하다가, yan님에게도 비슷한 취미가 있다는 것을 알게 되었습니다. 좋게 말해 취미일 뿐, 사실은 고약한 버릇에 가깝습니다. vim 애호가로 수렴한 사람들은 결국 비슷한 길을 걷게 되는 것일까요.
아무튼 k8s도 궁금한 부분에 로깅을 더해 빌드하고, 제가 빌드한 버전으로 하나씩 갈아 끼우는 작업을 하고 있습니다. 저와 같은 생각을 하는 사람이라면 십중팔구 kubectl 수정부터 시작할 것입니다.
kubectl 빌드
빌드 스크립트를 따라가 보면 cmd/kubectl을 빌드한다는 것을 알 수 있습니다. 별생각 없이 일단 빌드를 돌려 보면 1시간쯤 걸립니다. 그 결과로 아래와 같은 바이너리가 만들어집니다.
-rwxr-xr-x 1 sangwook sangwook 201M 6월 11 22:39 kube-apiserver
-rwxr-xr-x 1 sangwook sangwook 65M 6월 11 22:40 kubectl
-rwxr-xr-x 1 sangwook sangwook 141M 6월 11 22:39 kubelet
...코드를 한 번 고칠 때마다 빌드에 1시간을 기다려야 했습니다. 저는 쿠버네티스를 잘 모르는 사람이라, 모르면 이 정도는 참아야 한다고 여겼습니다. 빌드 스크립트를 파고드는 것이 목적은 아니었으니까요.
그러다 도저히 참지 못하고, 시간을 내어 빌드 스크립트를 읽었습니다. 그 덕에 빌드 시간을 9분에서 10분 정도로 줄였습니다. 이마저도 느려서 견디기 힘들지만, 더 빠르게 만드는 일은 시간이 남을 때 하기로 미뤄 두었습니다.
하지만 결국 10분을 기다리는 것조차 참지 못하고, 빌드 스크립트를 좀 더 자세히 들여다봤습니다. 예전에는 테스트 코드를 건너뛰는 옵션이 있었던 것 같은데, 지금은 그 옵션이 동작하지 않았습니다. 일단은 10분을 기다리는 쪽으로 타협했습니다.
kubespray가 kubectl과 kubelet을 업데이트하는 방식은 이렇습니다. hyperkube 이미지 안의 kubectl과 호스트의 kubectl을 바이트 단위로 비교한 뒤, 둘이 다르면 복사합니다. 이 부분은 kubespray 코드에서 볼 수 있습니다.
이제 제가 빌드한 kubectl을 쓰도록 바이너리 경로를 바꿉니다. 그다음 클러스터의 config를 ~/.kube/sangwook-cluster.conf로 복사하고, KUBECONFIG에 그 config 경로를 지정합니다. 이렇게 해 두면 kubectl 명령을 실행하면서 테스트할 수 있습니다.
apiserver 빌드
apiserver 빌드는 의외로 간단합니다. 도커 이미지만 만든 다음 이미지 주소를 바꾸면 됩니다. apiserver가 static pod로 정의되어 있어서, 주소를 바꾸면 manifest가 곧바로 적용됩니다. 도커 이미지를 만드는 데에는 몇 초밖에 걸리지 않습니다. hyperkube 하나만 만들면 10초쯤입니다.
이렇게 자주 수정하고 빌드하고 도커 이미지를 만들다 보면, 지금 돌고 있는 것이 방금 빌드한 버전이 맞는지 궁금해질 때가 있습니다. 제대로 배포가 되긴 한 것인지 확인하고 싶어지는 것입니다. 그럴 때는 빌드한 서버에서 docker images --digests를 실행해 digest의 sha256 값을 확인합니다.
REPOSITORY TAG DIGEST IMAGE ID CREATED SIZE
sangwook/hyperkube-amd64 v1.9.5-sangwook-custom sha256:71d332a5b8cdb21329b9ca75c5aae454fa3d60c8a87b6088aaeee1720a8850f4 944446664a2b 32 minutes ago 619MB그리고 apiserver를 배포한 서버에서 나오는 digest의 sha256이 이 값과 같은지 확인하면 됩니다. 여기서 IMAGE ID가 아니라 digest를 본다는 점이 핵심입니다.
CONTAINER ID IMAGE COMMAND CREATED STATUS
0b11ac196ea3 sangwook/hyperkube-amd64@sha256:71d332a5b8cdb21329b9ca75c5aae454fa3d60c8a87b6088aaeee1720a8850f4 "/hyperkube apiser..." 13 minutes ago Up 13 minutesetcd에 업데이트
etcd와 통신하는 로직이 궁금해서 코드를 따라가 봤습니다. 이렇게 코드를 따라가다 보면 스택을 자주 확인하게 되고, 스택의 각 지점에 해당하는 코드로 손쉽게 옮겨 다닐 수 있어야 합니다. 그래서 아래와 같은 vim 플러그인을 직접 만들어 쓰고 있습니다.
처음에는 kubectl get pods 같은 get 로직을 따라가 봤는데, 기억에 남을 만큼 특별한 점은 없었습니다. 그래서 etcd 변경이 일어나는 쪽을 봤습니다. 예를 들어 service의 nodePort를 kubectl로 바꾸면, 변경된 spec의 셀렉터와 바뀐 값만 request body에 담아 apiserver로 PATCH 요청을 보냅니다. apiserver는 그 요청을 받아 etcd를 업데이트합니다.
코드를 보다 보면 etcd를 덤프해서 변경 전후를 diff 하는 일을 자꾸 반복하게 됩니다. 처음에는 제대로 된 덤프 방법을 몰라서, key 목록을 가져온 뒤 하나씩 get하는 스크립트를 만들어 써야 했습니다. 분명 더 좋은 방법이 있을 것입니다. 지금은 etcd 값이 바뀌면 메시지를 받도록 k8s를 고쳤는데, 이 편이 훨씬 편했습니다.
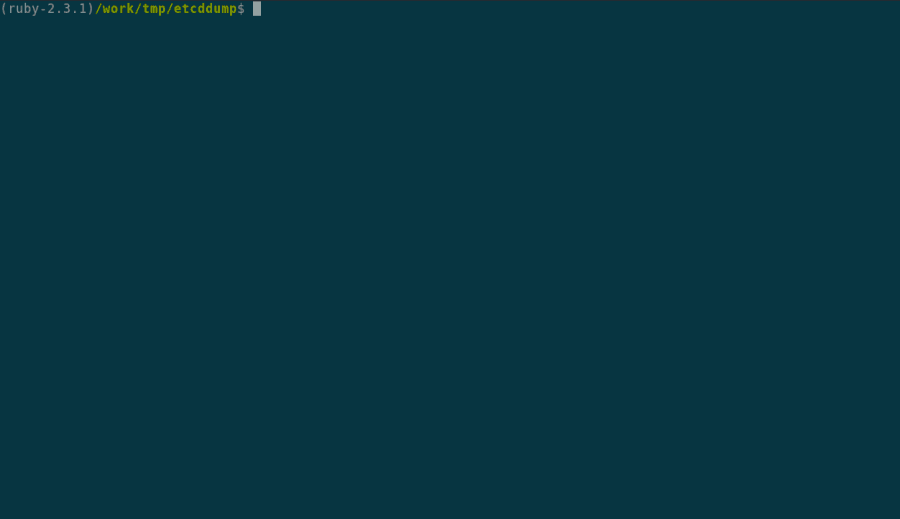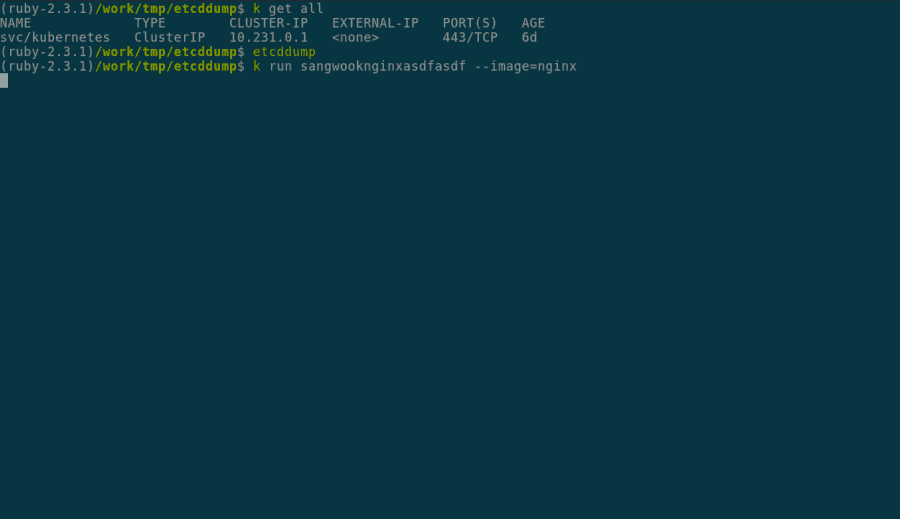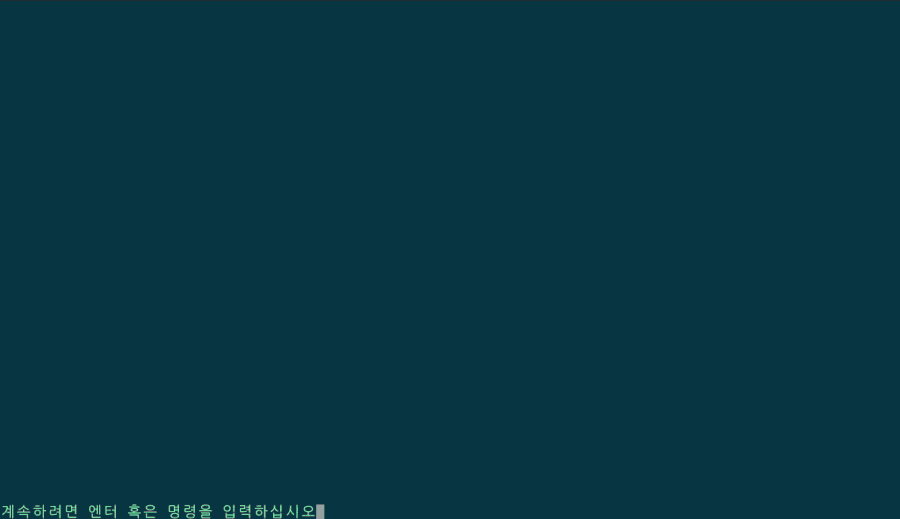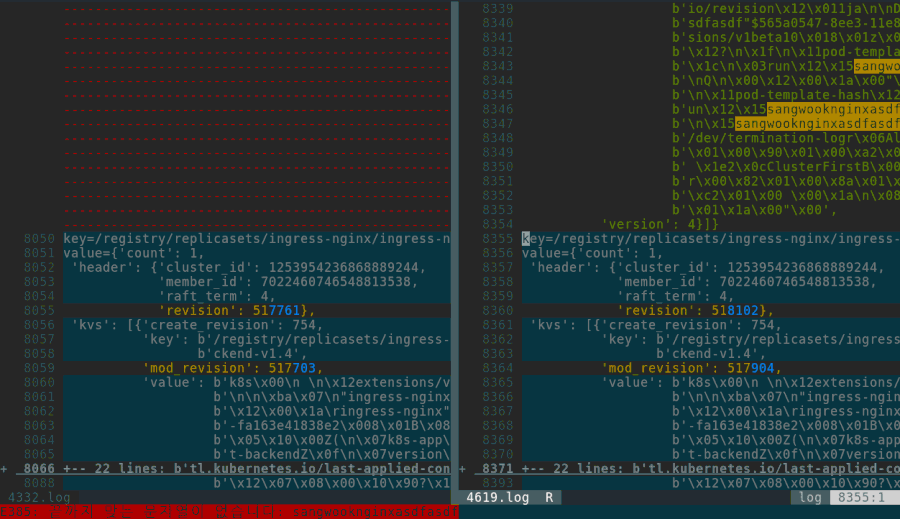
etcd에 저장하는 로직에서 재미있게 본 코드를 몇 군데 적어 둡니다. 리소스 업데이트는 모두 이 거대한 메소드 안으로 들어옵니다. 그리고 이 코드를 거쳐, etcd 업데이트를 끝까지 따라가면 이 지점에 이릅니다.
사실 저장하는 부분보다는 notify와 watch를 하는 부분이 핵심입니다. 그 밖에도 apiserver와 scheduler가 통신하는 로직, apiserver와 kubelet이 통신하는 로직이 흥미로웠습니다. kubectl create -f xxx.yaml로 Service를 nodePort로 생성할 때 services와 endpoints에 각각 한 번씩 모두 두 번의 POST를 보내고, 그에 맞춰 iptables를 바꾸는 로직도 재미있었습니다.
이런 것을 모두 여기에 정리하려니 벅찹니다. 게다가 저처럼 사소한 데에 마음을 쓰는 사람이 많지는 않을 것 같습니다. 그래서 오늘은 여기까지 적습니다.